The Messy Reality of Custom Document Pipelines
Why simple extraction scripts turn into fragile, scattered tech stacks, and how a unified system solves it.
It usually starts with a simple request: "We just need to extract three fields from these PDF contracts."
An engineer writes a quick script. They pipe the document through an open-source OCR tool, add a few regular expressions, and pass the text to a cloud AI endpoint. For the first ten clean documents, it works perfectly.
Then reality hits. A vendor uploads a scanned PDF with skewed multi-column layouts, nested tables without borders, and handwritten annotations in the margins.
The simple script breaks. The engineer adds coordinate mapping. Then they add a layout parser. Then a vector database to handle longer contexts. Suddenly, a three-day project snowballs into a fragile, 3,000-line monstrosity.
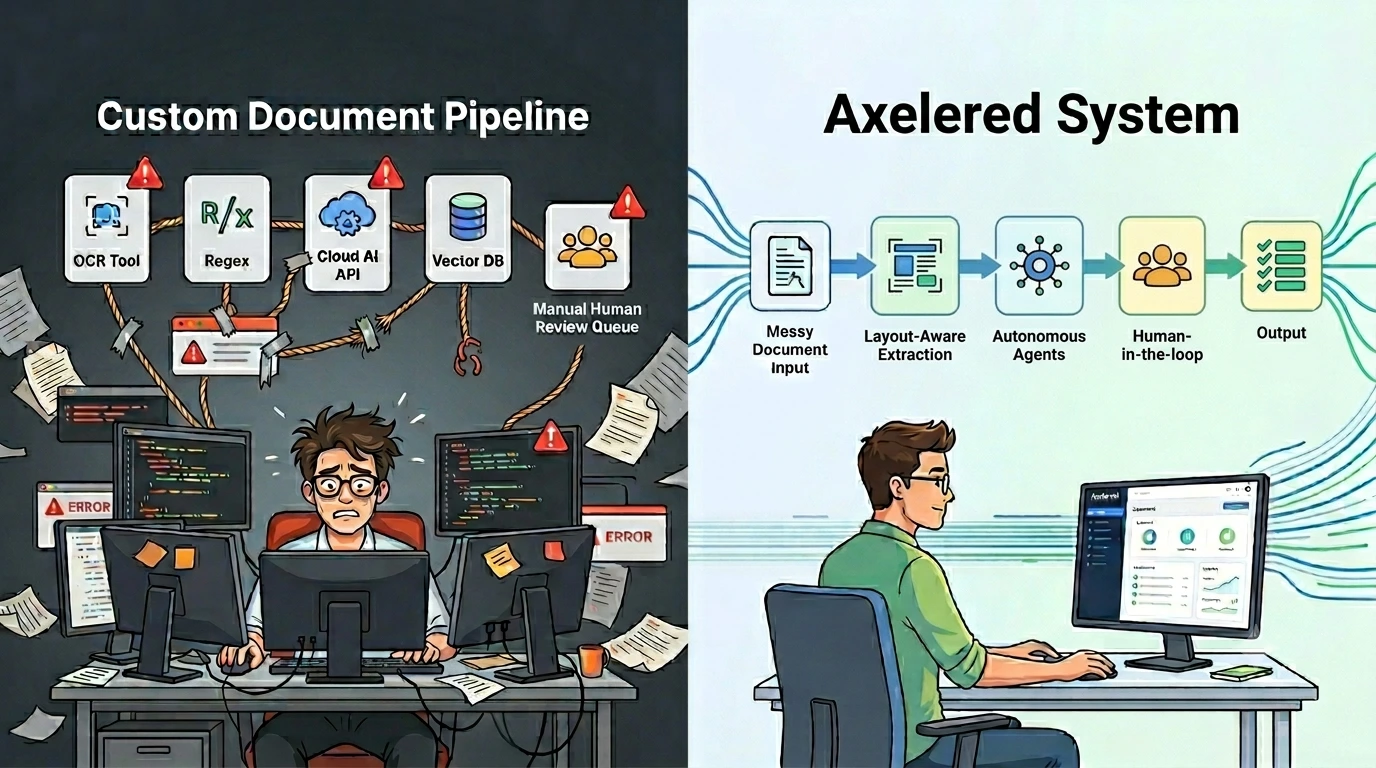
The fragmented stack
Building custom document pipelines requires gluing together entirely disconnected technologies. You are forced to maintain a fragile chain of OCR engines, layout parsers, vector databases, external cloud APIs, and custom database connectors.
A minor change in a document's layout instantly breaks this brittle logic. Table headers get hallucinated, data ends up in the wrong columns, and silent errors corrupt your database.
This creates massive development uncertainty. Engineering teams spend months duct-taping tools together, yet they can never guarantee the outcome on messy, real-world files.
The missing exception layer
The biggest failure in custom pipelines is how they handle uncertainty. AI is probabilistic. If an extraction only has a 60% confidence score, a custom pipeline has no built-in way to handle it safely.
Building a secure, real-time human review queue with frontend interfaces, role-based access controls, and routing logic is another three-month development cycle. Because this is so difficult to build from scratch, companies either let unchecked errors slip through or block the pipeline entirely when an edge case occurs.
A system built for the work
Enterprises shouldn't build custom document pipelines from scratch. They should deploy a system designed specifically for the task.
We built Axelered to replace this fragile, scattered stack. It is a cohesive system that coordinates autonomous agents to read, extract, structure, and edit documents out of the box.
Instead of patching together external APIs, the entire pipeline is unified. The system natively handles layout-aware parsing, field extraction, semantic classification, and intelligent redaction at scale.
More importantly, human control is a core architectural primitive. If an agent encounters a complex layout or low-confidence extraction, the document automatically routes to a built-in human review queue. Operators can securely validate or correct the data before it enters your database.
By deploying a pre-built, sovereign system with zero external dependencies, organizations eliminate development uncertainty. You stop maintaining glue code and start processing documents reliably from day one.